记一次webpack打包优化

开始接触vue的时候大概就是开始接触webpack的时候,用vue-cli直接脚手架工程后就开始开发了,用了一段时间后发现vendor.js越来越大,居然到了M的级别。看了一下vue-cli的默认配置,vendor是把node_modules里的依赖都打进vendor中,我觉得太大了这样,不如手动维护控制包的粒度,多分出几个包,充分利用浏览器并发请求资源的好处,而不是把所有东西都打进vendor中。
那个阶段开发任务重,没太多时间细细纠结,反正是迷迷糊糊看着webpack的配置文档和各种问题解决的帖子把上面提到的事儿做了。效果出来了,也就没再管过。这几天突然发现打包的地方还是有很多可以优化的点儿,便优化并记录一下。
这里着重的就是三个东西来完成此次优化:
- webpack.optimize.CommonsChunkPlugin
- OptimizeCssAssetsPlugin
- BundleAnalyzerPlugin
首先,记录一下目前线上的包有什么问题(这个项目是一个多入口的vue项目):
- 只抽离了vendor.js,却没有抽离各个入口的共有代码
- 每个入口模块的css也没有抽离出共有代码,导致500k的样式文件在每个入口的css文件里都有一份,浏览器缓存用不起来
- css文件没有压缩,去注释等优化工作,在线上直接裸奔,传输的大小过大
- 有些基础库虽然不是每个入口包都需要的,但迟早是需要的,是否也应该进一步优化出来成为一个单独的包引用,而不是打在各个入口包里
所以接下来我们就利用工具解决上面的问题到达优化的目的。
CommonsChunkPlugin 就是常用的提取各个包共有模块的工具,不过我觉得这个插件设计的不是那么易于理解和使用,文档看了有些懵。。。不过我还是按照自己的实验和理解来记录一下如何使用他。
在分析之前,我是一脸懵逼的,我只知道它打出的包不是我想要的,而不知道打出包的内容到底哪里不对,对整个出包的结果不清晰和不确定让我很抓狂,我不知道眼前的包是什么细节的,怎么优化呢?没错,无意间找到了默认就有的一个神器,只要开启一下BundleAnalyzerPlugin就可以图形化的观察打包的结果, 先上一张优化前的图:
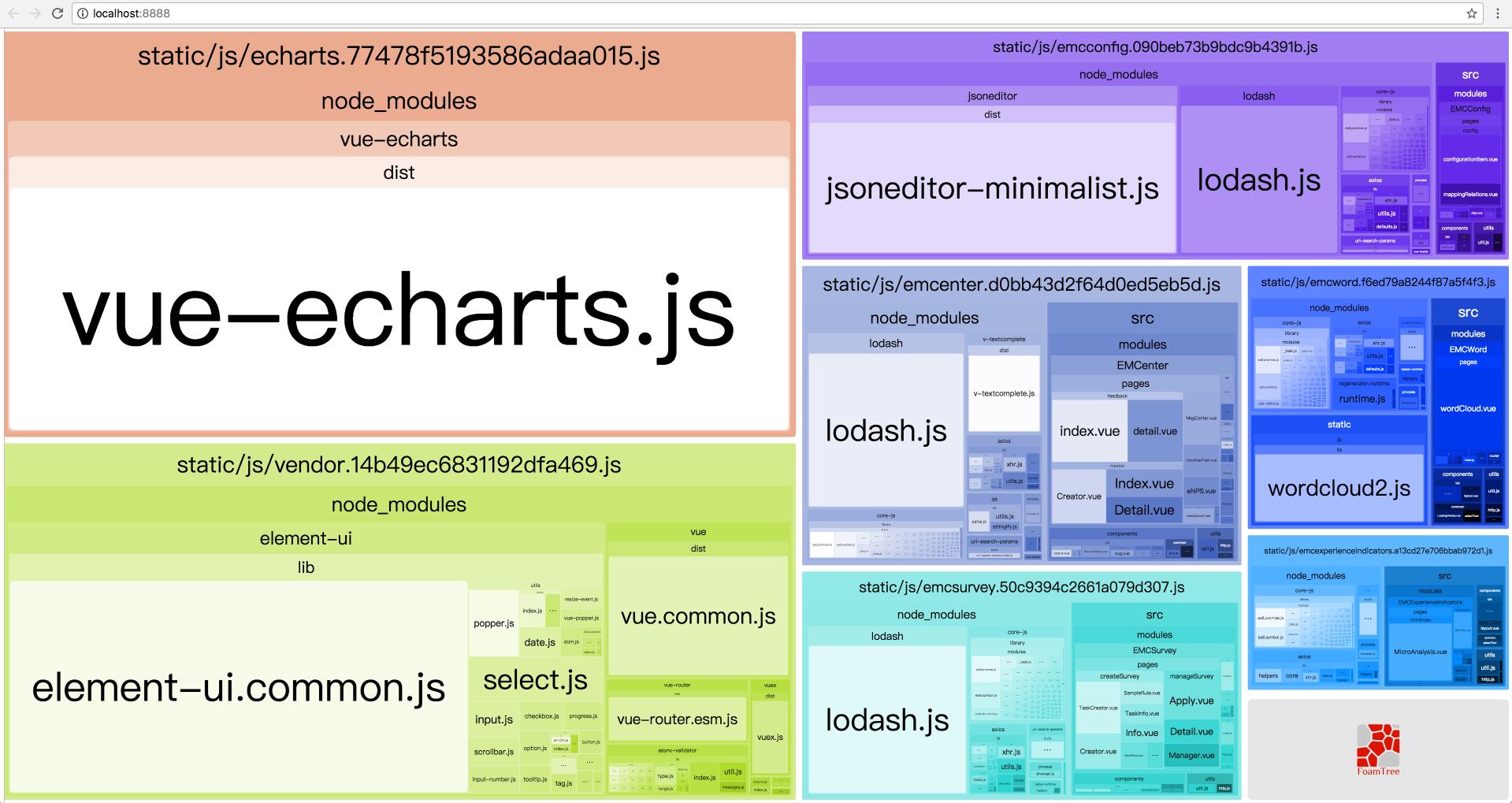
我们可以看出各个包的组成,里面明显的问题:
- lodash这个库挺大的,没有抽出来
- 各个入口文件的共有代码没有提出来,例如每个入口包里都有的模块:axios、core-js等
- 这个图里没有css(这里要记录一下,我可能才刚刚理解了一切皆模块的理论,为什么会有上面提到的第二个问题,原因就在这里,公共的代码没有提取出来的时候,js和css代码都不会有的,因为他们是一体的,虽然我们后来用ExtractTextPlugin插件把css提出来成了单文件,但模块这个概念其实是广义的,模块里不仅可以有js也可以有css,甚至任何资源。)所以要把各个入口的样式都提到一个共有文件里。
好的,目标确定了,然我们来改我们的配置,这里记录关键配置:
entry: {
// ... 这里的5入口模块文件就省略了
vendor: ['vue', 'vue-router', 'vuex', 'element-ui'],
echarts: ['vue-echarts'],
lodash: ['lodash']
}
可以看到在入口处,除了我们的入口文件声明,我们还声明了非入口包文件:
- vendor.js: 包含我们的主要技术栈模块vue, vue-router, vuex, element-ui。这些内容都是不轻易改变的,打成vendor可以很好的缓存起来,而且所有的入口文件都会用到vendor。
- echarts.js: 包含vue-echarts这个模块,没错,就是想把它单独拎出来好让浏览器缓存,我们是个后台系统,图表是常用组件,又由于这个组件特别大,600k+,所以单独成包。
- lodash.js: 是这次优化的点,常用基础款应该提出来。
以上手动维护自己的包文件构成,我觉得比vue-cli默认那种把node_modules都打进vendor来要好,因为我们可以更好的控制单个包文件的大小和粒度。
然后我们就需要配置CommonsChunkPlugin这个插件去完成公共包的抽离,并且命名为common.js,(如果你还记得一切都是模块,那么我们还会顺带完成我们另一个任务,即common.css), 配置如下:
plugins: [
new webpack.DefinePlugin({
'process.env': env,
}),
new webpack.optimize.UglifyJsPlugin({
compress: {
warnings: false
}
}),
new OptimizeCssAssetsPlugin({
assetNameRegExp: /\.css$/,
cssProcessorOptions: {
discardComments: { removeAll: true }
}
}),
// extract css into its own file
new ExtractTextPlugin({
filename: utils.assetsPath('css/[name].[contenthash].css')
}),
// 抽取公共模块
new webpack.optimize.CommonsChunkPlugin({
names: ['common', 'lodash', 'echarts', 'vendor']
}),
// 抽取 manifest
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
minChunks: Infinity
})
]
这个CommonsChunkPlugin不好理解的在于,它是一个隐式的配置,即 names: ['common', 'lodash', 'echarts', 'vendor'] 这个配置中数组中的模块顺序是有讲究的。。。可以看看这个issue:https://github.com/webpack/webpack/issues/1943
简单来说就是它们的依赖关系如下:
a ->
b -> common -> lodash -> echarts -> vendor -> manifest
c ->
就是入口文件a,b,c依赖common.js, common.js依赖lodash, 依次类推,但其实也许common.js不依赖lodash,但是由于数组是平的结构,不能表示树形结构,所以这么写没有问题,就是被依赖的包不提取依赖的模块到自己的包中罢了。。。好绕嘴。。。,我们肯定的是入口abc 一定依赖他们后面的东西(CommonsChunkPlugin不配chunks属性,默认是所有模块,所以common的声明会使得入口的公共代码被打进去,而像lodash echarts vendor这种我们声明的模块如果被common吸收了也会挪出去的,其实就是这个依赖链条你必须告诉webpack,这也就是说你只声明一个names: ['common']会打重复的包,因为webpack并不知道common和定义的包之间什么关系),所以记住数组中是:子模块 -> 父模块 这么一个顺序写的,子依赖父,而当我们用HtmlWebpackPlugin自动写入链接的时候,顺序刚好和声明相反,即:
<script type=text/javascript src=manifest.js >
<script type=text/javascript src=vendor.js >
<script type=text/javascript src=echarts.js >
<script type=text/javascript src=lodash.js >
<script type=text/javascript src=common.js >
<script type=text/javascript src=a.js >
这样就到达了我们的目的,至于manifest是什么,这又是一个问题,可以参考webpack官网或者https://github.com/webpack/webpack/issues/1315
这样我们同样提出了我们的common.css,然后利用OptimizeCssAssetsPlugin做了压缩。好了,然后让我们再打包一遍,看看是什么样子了:

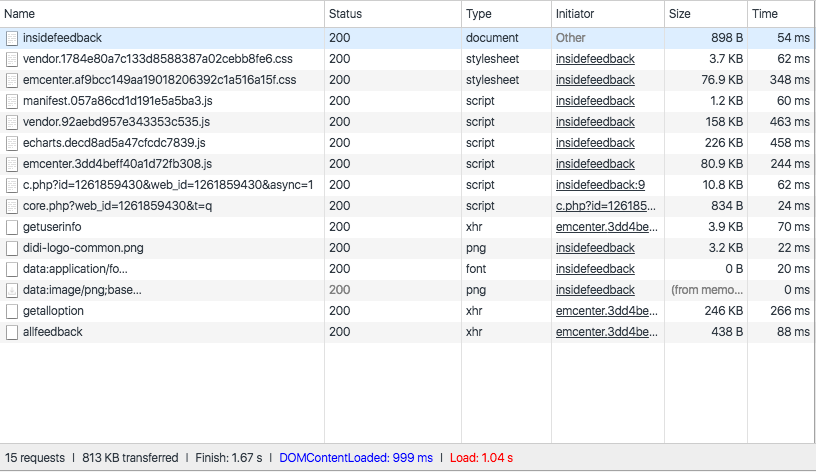
恩看起来一目了然,是我们想要的结果,由于观察不出css,和想要实地看看我们的收益,做了一下优化前后的网络性能截图。
- 优化前:
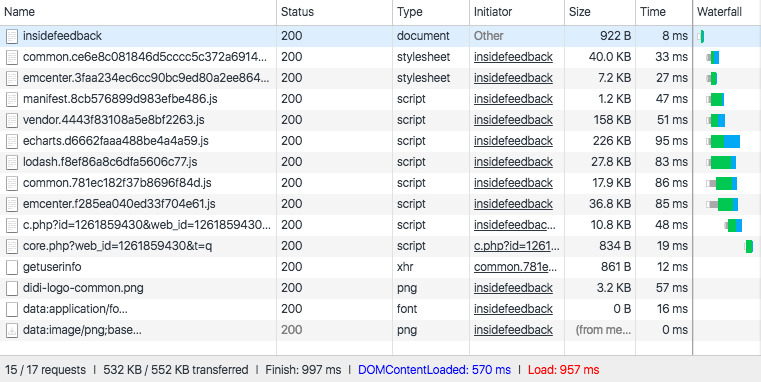
- 优化后
可以明显看出:
- 请求数量从15增加到了17,多了2个其实就是我们分离出的common.js和vendor.js
- 总大小从813kb缩小到552kb, 这归功于我们抽离出了common.css和做了大幅度的压缩
- 总的finish时长从1.67s压缩到了997ms, DOM加载完成的时间从999ms压缩到了570ms。这归功于整体的js和css分离和压缩
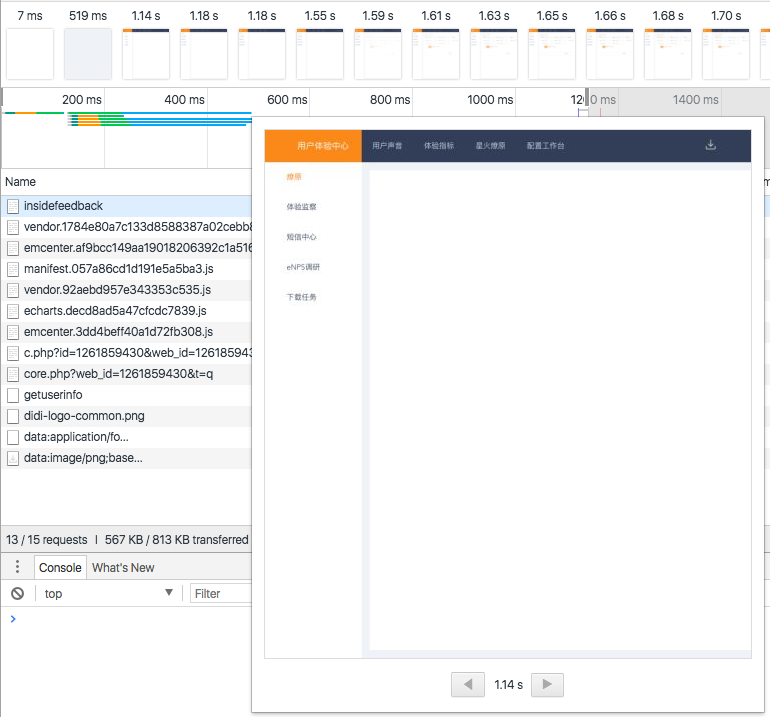
最后顺手记录了下白屏的影响:
-
优化前
-
优化后
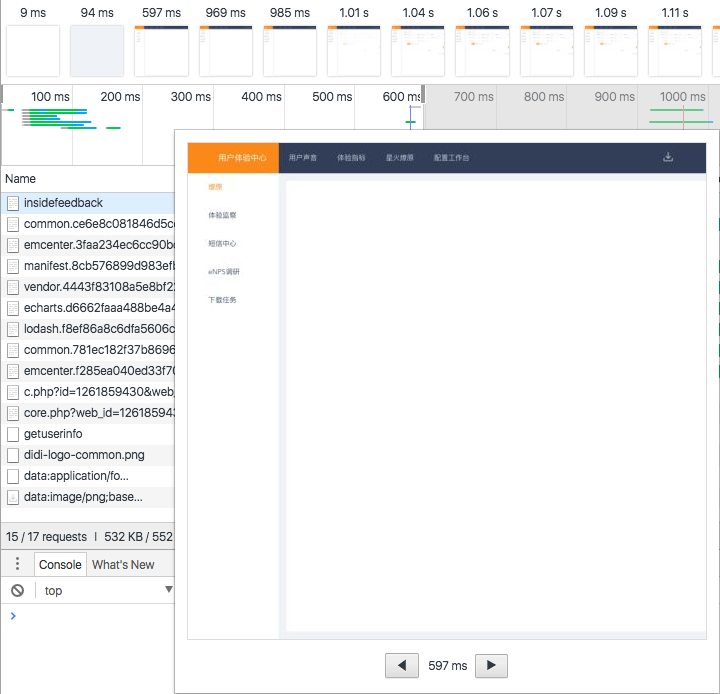
效果还是明显的,用户感知度更好,整体感知时间缩短了一半,从1.14s降低到了597ms,从秒级别降低到了毫秒级别。
ps:嗯嗯,最近发生了很多事儿,可是呢加油吧 ~ @simona祝顺利 ~